ollama就是用llama.cpp作为后端引擎来封装了模型下载、版本管理和API服务等便捷功能,ollama对旧的AMD显卡支持不好,这里干脆就切换到直接使用llama.cpp来在旧的AMD RTX6700显卡上本地部署大模型。
一、安装llama.cpp
winget install llama.cpp二、下载模型
1. 在模搭社区的模型库那里搜索你想要部署的模型, 例如:qwen3.5 9B GGUF
在搜索出来的结果中,选择一款模型,这里我们选择下载量最大的一个模型作为示例,这里用: unsloth/Qwen3.5-9B-GGUF
注意:
llama.cpp只支持.gguf格式的模型文件,所以这里搜索的时候一定要就加入GGUF关键字
2. 默认llama.cpp在Hugging Face下载模型,这里为了快速下载,打开Windows终端,设置PowerShell(终端)模型下载来源的环境变量为国内的模搭社区
$env:MODEL_ENDPOINT="https://www.modelscope.cn/"3. 使用llama-cli下载模型
llama-cli -hf unsloth/Qwen3.5-9B-GGUF下载并运行成功,默认会保存到:C:\Users\[用户]\AppData\Local\llama.cpp\目录下, 示例中保存的文件名为:unsloth_Qwen3.5-9B-GGUF_Qwen3.5-9B-Q4_K_M.gguf,如下图所示:
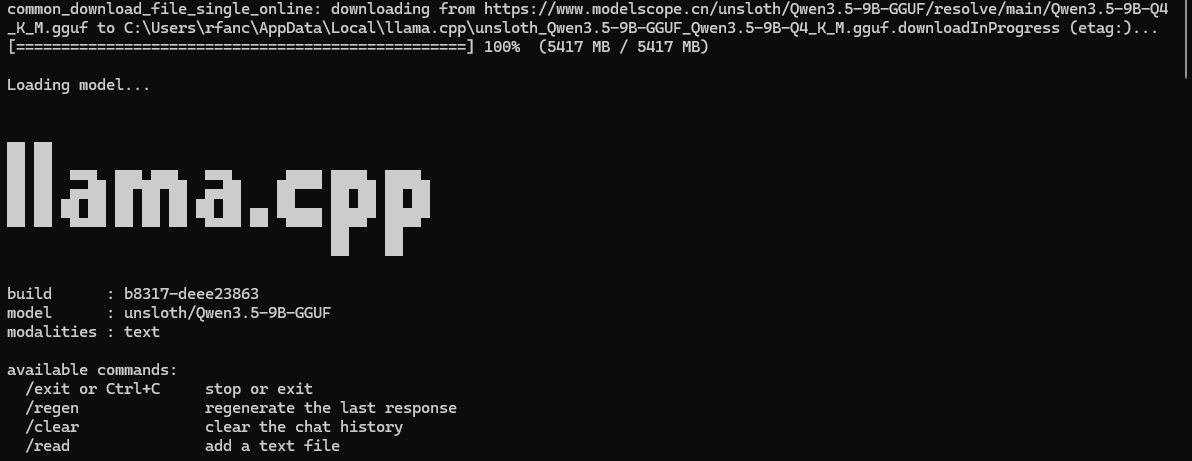
这里[用户]为你windows当前登录的用户名
4. 检查是否使用显卡跑的大模型
打开“任务管理器”->选择“性能”->选择“GPU 0”,如果能看到专用GPU内存占用了很大一部分或者被占满了,说明这时候GPU起作用了。
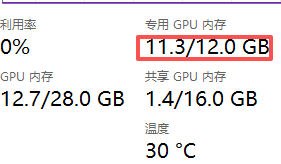
同时你如果退出llama.cpp,可以看到显卡内存占用从11.3G降到了1.3G
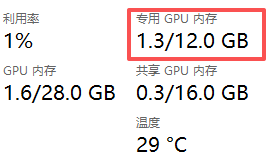
同时你可以很明显的感受到大模型回复你的问题的时候文字吐出来的速度快了很多。
三、运行模型
llama-cli -m /path/to/unsloth_Qwen3.5-9B-GGUF_Qwen3.5-9B-Q4_K_M.gguf例如:
llama-cli -m C:\Users\admin\AppData\Local\llama.cpp\unsloth_Qwen3.5-9B-GGUF_Qwen3.5-9B-Q4_K_M.gguf这里可以看到提示词输入是9.9 token/s, 输出是: 49.4 token/s

- 这里你可以把你下载的大模型文件移动保存到任何位置,执行
-m命令的时候指定正确的文件路径就好- 模型的加载放在机械硬盘上明显的有延迟,条件允许的话将模型文件放在SSD硬盘上会更合适
四、小技巧
1. 开启llama.cpp自带的OpenAI API兼容的轻量级的HTTP服务
在8080端口启动HTTP服务,用户可以在浏览器输入http://127.0.0.1:8080开始与大模型对话
./llama-server -m /path/to/模型 --port 80802. 进阶设置
2.1 模型加载与硬件加速 (最关键)
| 参数 | 简写 | 含义 | 什么情况下使用 |
|---|---|---|---|
--model |
-m |
指定 GGUF 模型文件路径。 | 必选。启动服务时必须指定要加载的模型。 |
--n-gpu-layers |
-ngl |
GPU 卸载层数。将模型的多少层转移到 GPU 显存中。 | 强烈推荐。如果你有 NVIDIA/AMD/Intel 显卡,设置此值以加速。 • 全卸载: 设为一个大数字(如 99 或 100),让所有层都进显存。 • 部分卸载: 显存不足时,减小该值,剩余层用 CPU 跑。 • 纯 CPU: 不写此参数或设为 0。 |
--flash-attn |
-fa |
启用 Flash Attention 优化。 | 高性能需求。如果你的显卡支持(如 RTX 30/40 系列),开启后可显著提升长文本推理速度并降低显存占用。 |
2.2 并发与多用户支持 (Server 核心能力)
| 参数 | 简写 | 含义 | 什么情况下使用 |
|---|---|---|---|
--parallel |
-np |
最大并发槽位数 (Parallel Sequences)。 | 多用户场景。默认是 1。如果你要搭建 API 服务给多人用,设为 4, 8, 16 等。 • 注意: 增加此值会线性增加显存占用 (KV Cache)。 |
--ctx-size |
-c |
上下文窗口大小 (Context Window)。 | 长文档/长对话。默认通常较小 (如 4096)。如果需要处理长文档或维持长记忆,调大此值 (如 16384, 32768, 131072)。 • 代价: 显存占用会随上下文长度大幅增加。 |
--defrag-thold |
触发 KV 缓存碎片整理的阈值。 | 高负载优化。在长时间高并发运行后,显存可能产生碎片。调整此阈值可优化长期运行的稳定性(通常默认值即可)。 |
2.3 网络与服务配置
| 参数 | 简写 | 含义 | 什么情况下使用 |
|---|---|---|---|
--port |
-p |
监听端口号。 | 自定义端口。默认是 8080。如果端口被占用或需要特定防火墙规则,修改此项。 |
--host |
监听地址 (IP)。 | 远程访问。默认是 127.0.0.1 (仅本机)。• 局域网访问: 设为 0.0.0.0 允许局域网内其他设备访问。• 公网访问: 设为 0.0.0.0 并配置端口转发 (需注意安全)。 |
|
--api-key |
设置 API 密钥。 | 安全防护。如果你的服务暴露在公网或非信任网络,设置此参数,客户端请求时需在 Header 中携带 Authorization: Bearer <key>。 |
|
--api-key-file |
指定设置了API 密钥的文件。 | 如果不想密钥在命令行启动时被显示出来,可以保存到密钥文件中 | |
--ssl-key-file |
指定SSL私钥文件。 | 启用 HTTPS (SSL/TLS),防止数据明文传输, 指定PEM编码的SSL私钥文件。 | |
--ssl-cert-file |
指定SSL证书。 | 启用 HTTPS (SSL/TLS),防止数据明文传输,指定PEM编码的SSL证书。 |
2.4 提示词与聊天模板
| 参数 | 简写 | 含义 | 什么情况下使用 |
|---|---|---|---|
--reasoning |
-rea |
是否在聊天中开启深度思考。 | 强制模型是否开启深度思考模式,on: 开启,off: 关闭,auto: 由聊天模板决定,如果没有指定聊天模板,由模型的meta直接给出结果” |
--chat-template |
强制指定聊天模板。 | 如果未指定,llama.cpp 一般会从模型文件中的metadata中获取,如果模型回复格式混乱,可手动指定(如 kimi-k2, deepseek3)。 |
五、API支持
1. 可以运行以下命令开启Http API服务
下面命令在8080端口监听所有请求,并发请求设置为1,尝试将所有参数加载到GPU,上下文设置为8K,使用密钥文件中的密钥,最后将模型别名设置为qwen3.5。
llama-server -m 模型文件 --host 0.0.0.0 --port 8080 --parallel 1 --n-gpu-layers 99 --ctx-size 8192 --api-key-file 密钥文件 --alias qwen3.52. 创建一个api_key.txt的密钥文件,里面保存你创建的api_key,注意:这里只支持一个密钥
3. API相关参数
OPENAI_BASE_URL="http://你的IP:8080/v1"
OPENAI_API_KEY="你的密钥"4. 模型信息
模型信息获取:http://localhost:8080/v1/models
{
"models": [
{
"name": "qwen3.5",
"model": "qwen3.5",
"modified_at": "",
"size": "",
"digest": "",
"type": "model",
"description": "",
"tags": [
""
],
"capabilities": [
"completion"
],
"parameters": "",
"details": {
"parent_model": "",
"format": "gguf",
"family": "",
"families": [
""
],
"parameter_size": "",
"quantization_level": ""
}
}
],
"object": "list",
"data": [
{
"id": "qwen3.5",
"aliases": [
"qwen3.5"
],
"tags": [
],
"object": "model",
"created": 1773573049,
"owned_by": "llamacpp",
"meta": {
"vocab_type": 2,
"n_vocab": 248320,
"n_ctx_train": 262144,
"n_embd": 4096,
"n_params": 8953803264,
"size": 5669554176
}
}
]
}4. 示例python
import time
from openai import OpenAI
# 初始化客户端
client = OpenAI(
# 关键点:base_url 必须以 /v1 结尾
base_url="http://127.0.0.1:8080/v1",
api_key="" # 这里为api_key.txt中的密钥, 如果没设 --api-key,这里填任意字符串即可
)
# 1. 记录开始时间 (单位:秒)
start_time = time.time()
# 调用聊天接口
response = client.chat.completions.create(
model="qwen3.5", # 这里填模型 ID,通常可以是文件名
messages=[
{
"role": "system", "content": "你是一位私人助理,请不要进入深度思考模式,直接给出答案。"
},
{
"role": "user", "content": "请介绍以下你自己。"
}
],
extra_body={
"chat_template_kwargs": {"enable_thinking": False}
}
)
# 2. 记录结束时间
end_time = time.time()
# 3. 计算耗时
duration = end_time - start_time
# 5. 输出性能统计
print(f"\n⏱️ 总耗时: {duration:.4f} 秒")
print(response.choices[0].message.content)